Indexes are secret for faster query execution when designed properly.
Types of indexes in SQL Server :
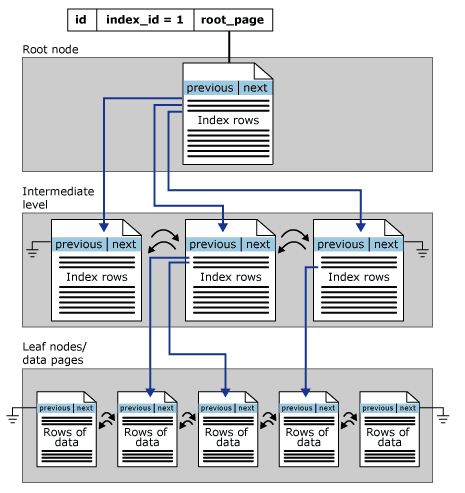
1. Clustered Indexes: A clustered index determines the physical order of data in a table. A clustered index is analogous to a telephone directory, which arranges data by last name.
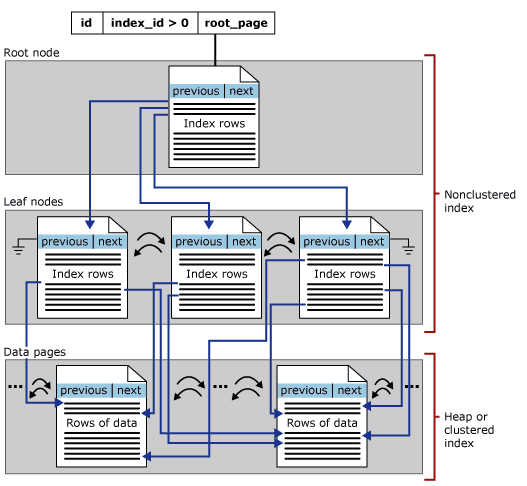
2.Non-Clustered Indexes: Nonclustered indexes have the same B-tree structure as clustered indexes, except for the following significant differences:
• The data rows of the underlying table are not sorted and stored in order based on their nonclustered keys.
• The leaf layer of a nonclustered index is made up of index pages instead of data pages.
Nonclustered indexes can be defined on a table or view with a clustered index or a heap. Each index row in the nonclustered index contains the nonclustered key value and a row locator. This locator points to the data row in the clustered index or heap having the key value.
Now let us discuss, what is Bookmark lookup and RID Lookup:
If query is using a non clustered index on a table that has clustered index then, it uses bookmark lookup (or key lookup) on Clustered Index to find the rest of the data.
If query is using a non clustered index on a table which is a heap (table does not have clustered index) then it uses a RID lookup to find the data.
The structure of a Non Clustered index can be shown below from Microsoft Site:
The structure of a Clustered index can be shown below from Microsoft Site:
Normally, when you get index recommendations by DTA and missing indexes DMV then are mostly for any Clustered indexes which are missing and also they are either Covering indexes for a query or index with include columns which are used in the query for avoiding Key lookup/Bookmark lookup or any RID lookup which reduces the performance of query.
We can improve the performance of query by using included column index or cover index in many scenarios but also make no duplication of indexes are done to avoid potential impact on Dml statements, maintenance window and size of the database.
1. Covering indexes: covers all the columns used in query’s “where clause” in the index plus any columns in “Select” of the query.
SELECT FirstName, LastName
FROM DemoEmp
WHERE City = 'London' and LastName = ‘Andrew’
Then the covering index would be
CREATE NONCLUSTERED INDEX [IX_NonClus_Cover] ON [dbo].[DemoEmp]
(
City, FirstName,Lastname
) ON [PRIMARY]
GO
2. Included Column indexes: Included Column indexes built index on columns in “where Clause” with included columns data stored.
SELECT FirstName, LastName
FROM DemoEmp
WHERE City = 'London' and LastName = ‘Andrew’
Then the included column index would be
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname
) INCLUDE (FirstName) ON [PRIMARY]
GO
Other things while considering indexes are Consolidating indexes based on Left based Set.
Say you have two indexes like below:
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname
) INCLUDE (FirstName) ON [PRIMARY]
GO
And
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname, Address
) INCLUDE (FirstName) ON [PRIMARY]
GO
Then there is no need for the first index as its already covered in second one.
Now consider another scenario below
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname, Address
) INCLUDE (FirstName) ON [PRIMARY]
GO
and
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname
) INCLUDE (FirstName), [Email] ON [PRIMARY]
GO
Then creating a new index below and then dropping above two would be called consolidating indexes.
CREATE NONCLUSTERED INDEX [IX_NonClus_Included] ON [dbo].[DemoEmp]
(
City, Lastname, Address
) INCLUDE (FirstName), [Email] ON [PRIMARY]
GO
Missing indexes DMV and DTA can be horribly misleading by creating individual indexes instead of one consolidated index like above. This where a DBA needs to take the wise decision.
Index creation is always been a R&D process where you constantly monitor the performance and add them/remove them where necessary if allowed in the Environment.
The above consolidation also saves space on the Server.
So now question arises about a large Database with thousands of tables/indexes then I would say it is best to start finding the top monster queries first and analyze them first to create the indexes which can be helpful.
Next thing is that we concentrate on Fragmentation level occurring on a index per day basis and per week basis. If a Index is fragmented very quickly then we should consider using a fill factor to properly adjust the updates and inserts.
Reorganization is a online process but Rebuild needs a table level lock which is offline activity unless used with online=on clause.
Read my another article which covers the Reorganizing and Rebuilding indexes with Pros and Cons.
Learn about SQL Server detecting logical consistency based issues and how to resolve them.
Learn about SQL Server error 1222 and how to resolve the lock request time out…
Discover the new features of Microsoft SQL Server 2022 and how they compare to previous…
SQL Server Error 1222 lock request time out period exceeded Lock request time out…
SQL Server Error : 427, Severity: 20. Could not load the definition for constraint ID…
SQL Server Error : 204, Severity: 20. Normalization error in node %ls.
This website uses cookies.
{kind=link}
{kind=link}